Как мы делали веб-интерфейс для Google Photos: заглядываем под капот
Перевод статьи Building the Google Photos Web UI с сайта medium.com для CSS-live.ru, автор — Антин Харасимив
Несколько лет назад мне посчастливилось стать инженером в команде Google Photos и поучаствовать в их первом запуске в 2015-м. Множество людей вложило силы в этот продукт — дизайнеры, продукт-менеджеры, исследователи и бесчисленные инженеры (в области Android, iOS, веба и серверной части), если упомянуть лишь некоторые важные роли. Я отвечал за пользовательский веб-интерфейс, а точнее, за сетку с фотографиями.
Мы хотели попробовать что-то масштабное и при этом поддерживать раскладку с равномерным выравниванием по всей ширине, сохранять пропорции каждого снимка, сделать интерфейс листаемым (т.е. чтобы было можно перескакивать к любому разделу своего архива), справляться с сотнями тысяч фото, обеспечить скроллинг с 60fps и практически мгновенную загрузку.
На тот момент никакая другая фотогалерея не поддерживала всего этого, и, насколько мне известно, не поддерживает и сейчас. Хотя сейчас у многих других галерей есть некоторые из этих возможностей, обычно они обрезают каждое фото до квадрата, чтобы раскладка заработала.
Ниже я подробно расскажу о том, как мы справились с этими сложностями, и загляну под капот веб-версии Google Photos, как она работает.
Почему это было так трудно?
Две крупнейшие трудности сводятся к размеру.
Первая проблема с размером в том, что для пользователей с огромными коллекциями фото (а у некоторых пользователей было загружено по четверти миллиона и более снимков) попросту слишком много метаданных. Отправка даже минимальной информации (адреса фото, ширина, высота и метки времени) — многие мегабайты данных для целой коллекции, что прямо противоречило нашей цели почти мгновенной загрузки.
Вторая проблема с размером — сами фото. С теперешними экранами сверхвысокого разрешения даже крошечные миниатюры фотографии часто бывают по 50 Кб и больше. Тысяча миниатюр — уже 50 мегабайт, и это не просто много для загрузки, если пытаться сразу же размещать их все на странице, можно «повесить» браузер. Старая версия Google+ Photos начинала тормозить при скроллинге через 1000–2000 снимков, а вкладка в Chrome в конце концов «вылетала» после загрузки 10000.
Давайте обсуждать проблему по частям (можете прокручивать прямо до соответствующего заголовка жирным шрифтом).
- Листаемые фотографии — возможность быстро перескакивать к любой части библиотеки снимков.
- Раскладка по всей ширине — заполнить ширину браузера и сохранить пропорции каждого снимка (никакой обрезки до квадрата).
- Скроллинг с 60fps — обеспечить, чтобы страница была отзывчивой даже при просмотре многих тысяч фото.
- Ощущение мгновенности — минимизировать время ожидания загрузки чего бы то ни было.
1. Листаемые фотографии
Есть много подходов к работе с большими коллекциями. Старейший, пожалуй — постраничный вывод (пагинация), когда вы показываете конечное число результатов и кликаете «дальше», чтобы посмотреть следующую порцию, и так до посинения. Более популярный современный подход — бесконечный скроллинг, названный так потому, что, загрузив ограниченное число результатов, по мере скроллинга к его концу вы подгружаете следующую порцию и вставляете ее на страницу, и так раз за разом; если всё сделано правильно, пользователь может скроллить постоянно (как будто бесконечно), не прерываясь.
Общий недостаток пагинации и бесконечного скроллинга в том, что нужно загрузить весь старый контент, чтобы добраться до конца, так что поиск фото многолетней давности может оказаться той еще работенкой.
Для обычных документов скроллбар работает ожидаемо, более того, можно взяться за ползунок и быстро промотать через целые разделы прямо к концу, или в любое другое место. С пагинацией скроллбар упрется в конец страницы (но не библиотеки), а для бесконечно прокручиваемой страницы скроллбар всё время меняется, при перетягивании до конца он немного отскакивает обратно, потому что страница становится длиннее.
Листаемая фотогалерея представляет третий вариант, где скроллбар работает правильно.
Чтобы можно было перескакивать к любому разделу фотографий, нам нужно заранее выделить место на странице, чтобы скроллбар был информативным. Это было бы относительно легко, будь у нас информация по всем картинкам, но поскольку для пересылки ее слишком много, нам нужно сделать иначе.
Именно здесь многие из других листаемых галерей упрощают себе задачу — они обрезают все фото до идентичной квадратной формы. Таким образом, для расчета всей раскладки страницы нужно знать только общее количество снимков: для заданного размера квадрата можно элементарно взять ширину окна и рассчитать по ней количество рядов и колонок:
const columns = Math.floor(viewportWidth / (thumbnailSize + thumbnailMargin)); const rows = Math.ceil(photoCount / columns); const height = rows * (thumbnailSize + thumbnailMargin);
Всего тремя строками кода задача с размерами решена, и теперь для отображения и размещения снимков нужен еще всего десяток.
Подход, который мы придумали для уменьшения начального размера метаданных — разделить коллекцию фотографий на отдельные разделы, и при первой загрузке отсылать разделы и количества. Например, можно просто разбить снимки по месяцам — можно посчитать их на сервере (или вообще заранее), и даже для миллионов фото, охватывающих десятилетия, это всё еще разумное количество данных. Простейшее представление этих данных может выглядеть вот так:
{
"2014_06": 514,
"2014_05": 203,
"2014_04": 1678,
"2014_03": 973,
"2014_02": 26,
// etc...
"1999_11": 212
}
В крайних случаях с этим всё еще могут быть проблемы у пользователей, у которых много фотографий за определенный месяц (напр. профессиональных фотографов) — задача разделов уменьшить каждую порцию до разумного количества метаданных, но у активных пользователей месяц всё равно может содержать тысячи снимков (и, стало быть, мегабайты данных). К счастью, наши молодцы из команды инфраструктуры превзошли сами себя и сделали сложное решение, учитывающее всё на свете (напр. геолокацию, близость времени съемки и т.д.), которое создает для каждого пользователя свои разделы.
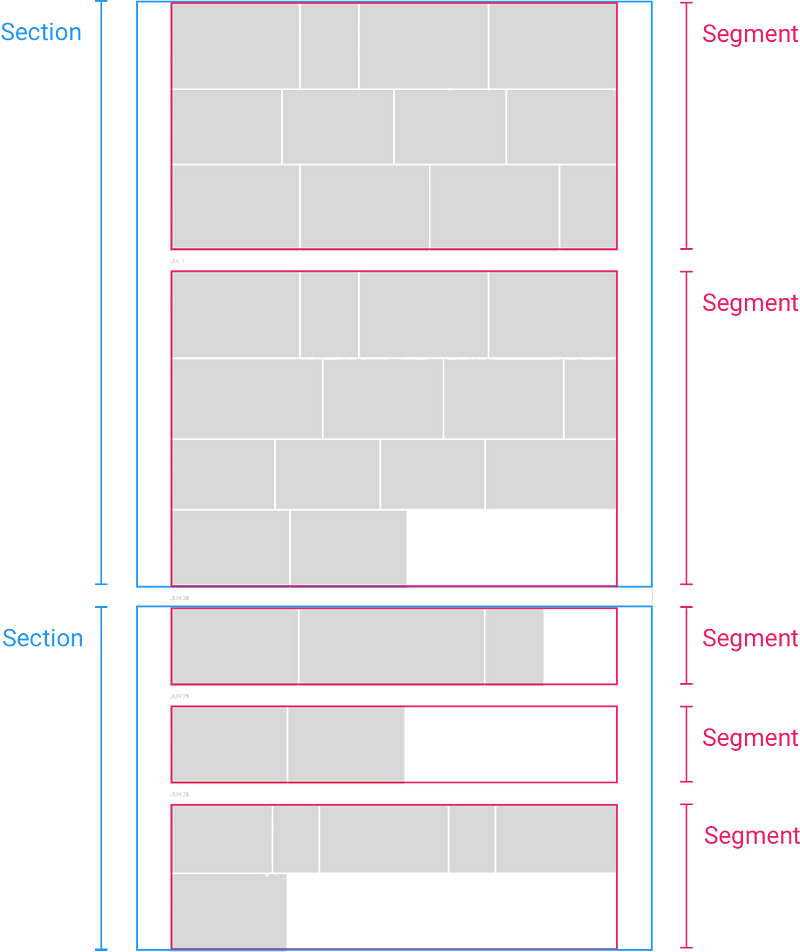
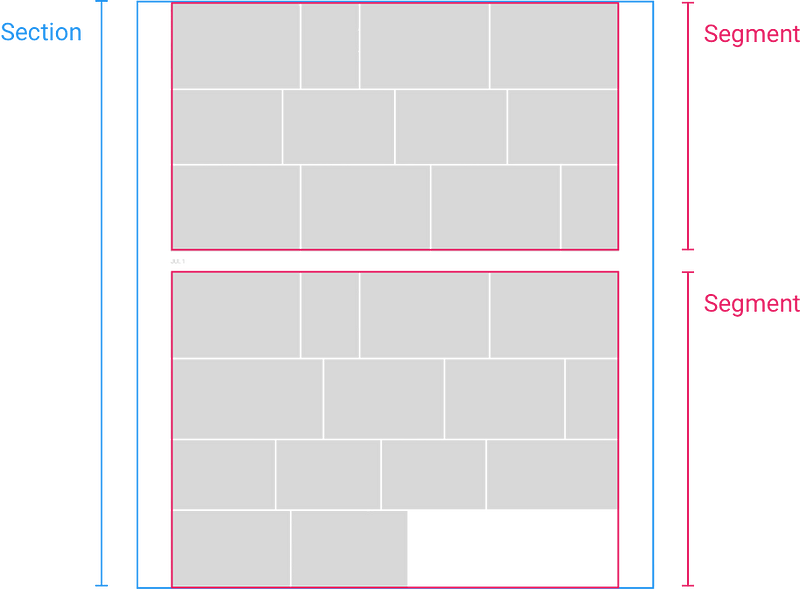
Сетка с фотографиями разделена на разделы (Section), сегменты (Segment) и плитки
С этой информацией браузер может оценить, сколько места понадобится каждому разделу, и вставить в DOM заглушку, а когда пользователь скроллит быстро, получить соответствующие метаданные с сервера, рассчитать всю раскладку и обновить страницу.
На стороне клиента, как только у нас появились метаданные для раздела, мы переходим к следующему шагу и разбиваем снимки в каждом разделе на сегменты по отдельным дням. Мы думали о динамическом разбиении (напр. по месту, человеку, дате и т.д.), которое еще может стать полезной возможностью в будущем.
Оценить размер раздела оказалось весьма легко, просто берете количество снимков для раздела и умножаете на наилучшее предположение о нормальных пропорциях:
// В идеале мы бы взяли средние пропорции для набора фото, но можно исходить из // типичных пропорций пейзажного кадра 3:2, затем сделать поправку на вероятность // того, что фотографии придется уменьшать и объединять. const unwrappedWidth = (3 / 2) * photoCount * targetHeight * (7 / 10); const rows = Math.ceil(unwrappedWidth / viewportWidth); const height = rows * targetHeight;
Спросите, как вообще это может быть сколь-либо точным? В том-то и дело, что это не точно, даже близко.
Удачно, что я поначалу переоценил эту часть задачи (почему — я объясню в разделе «Раскладка»), но оказывается, что очень хорошая оценка вам и не нужна (и при большом числе снимков она нередко ошибается на десятки тысяч пикселей). Единственное, что здесь важно — чтобы эта оценка давала примерное представление о масштабе, так что скроллбар будет выглядеть правильно.
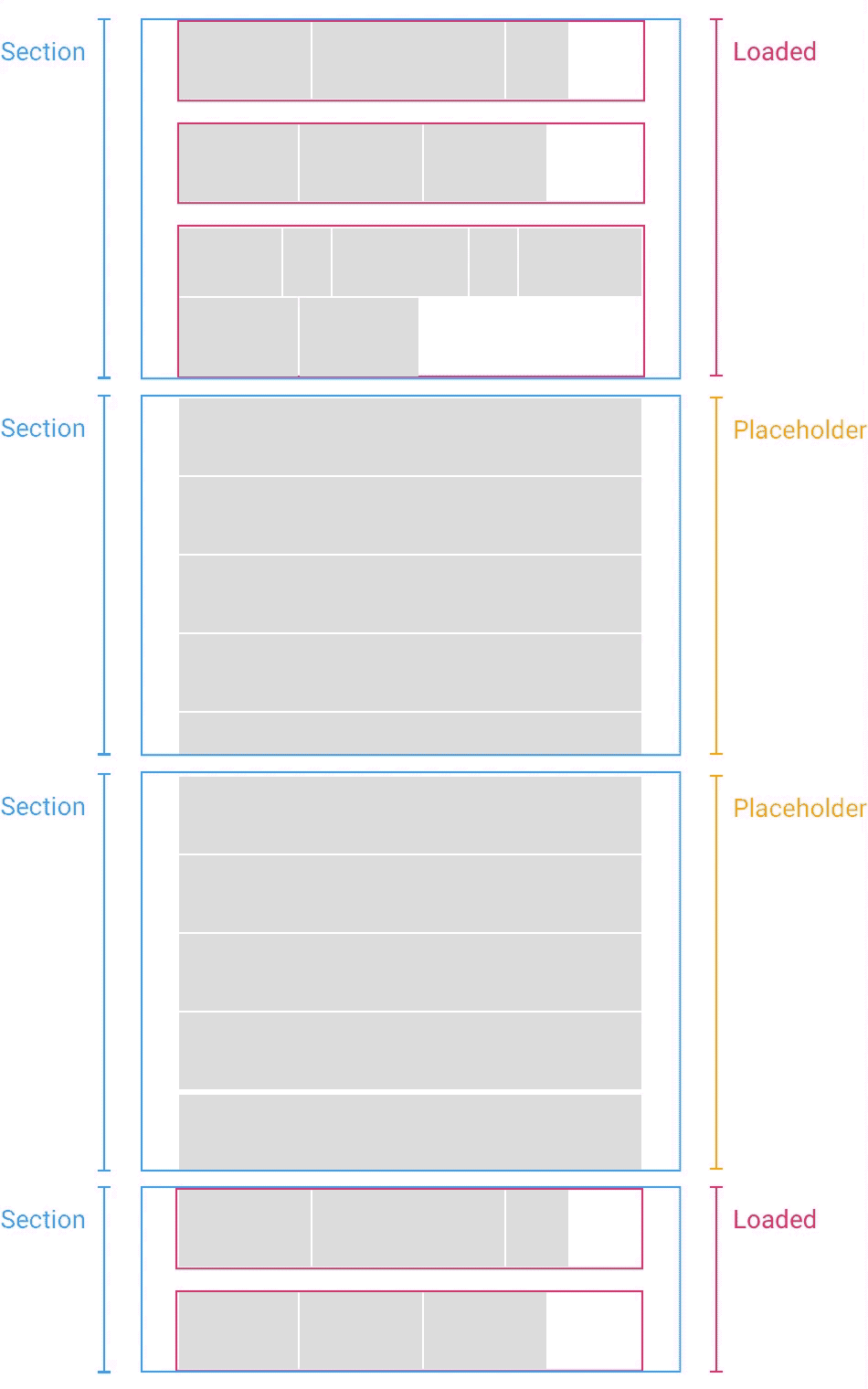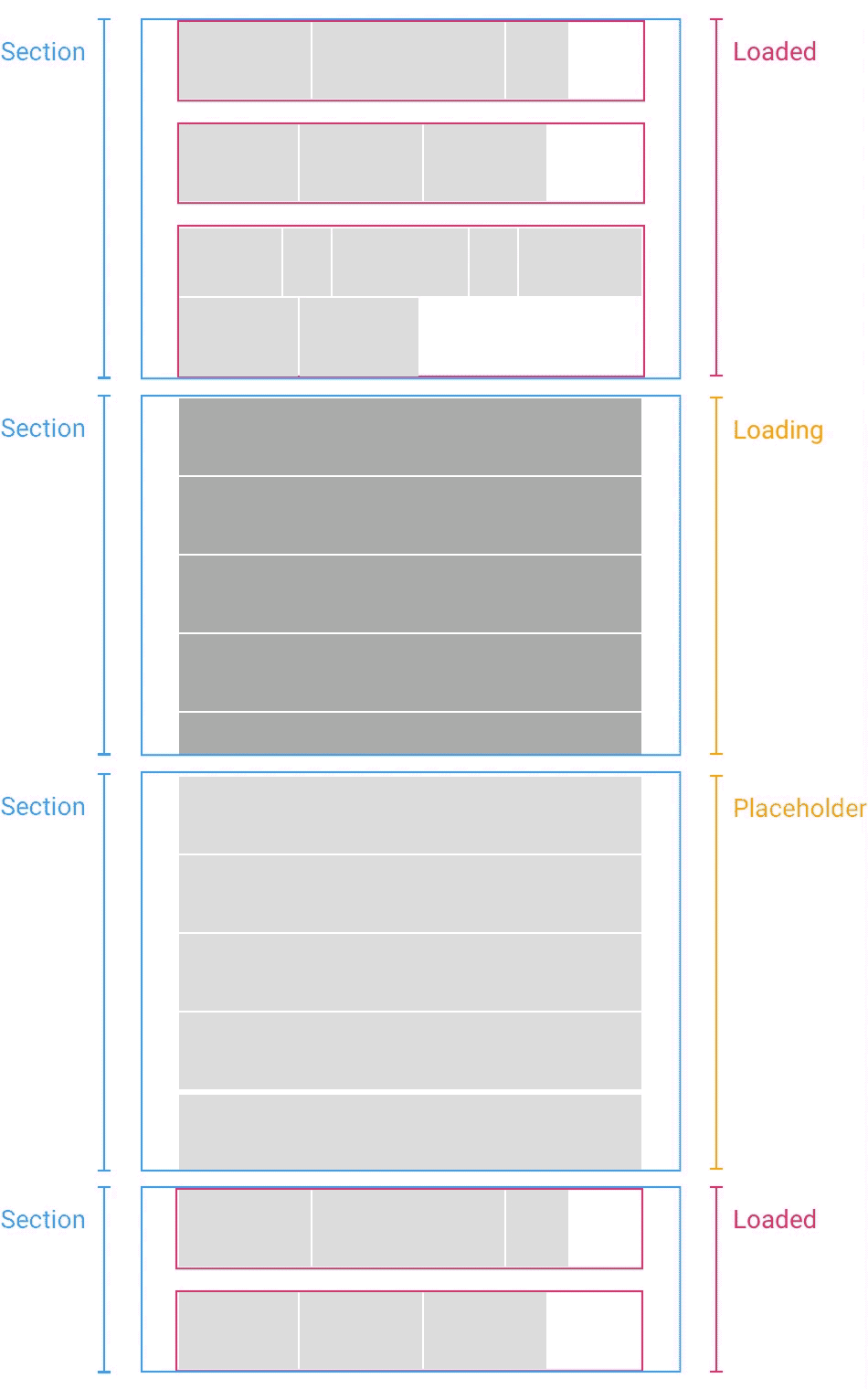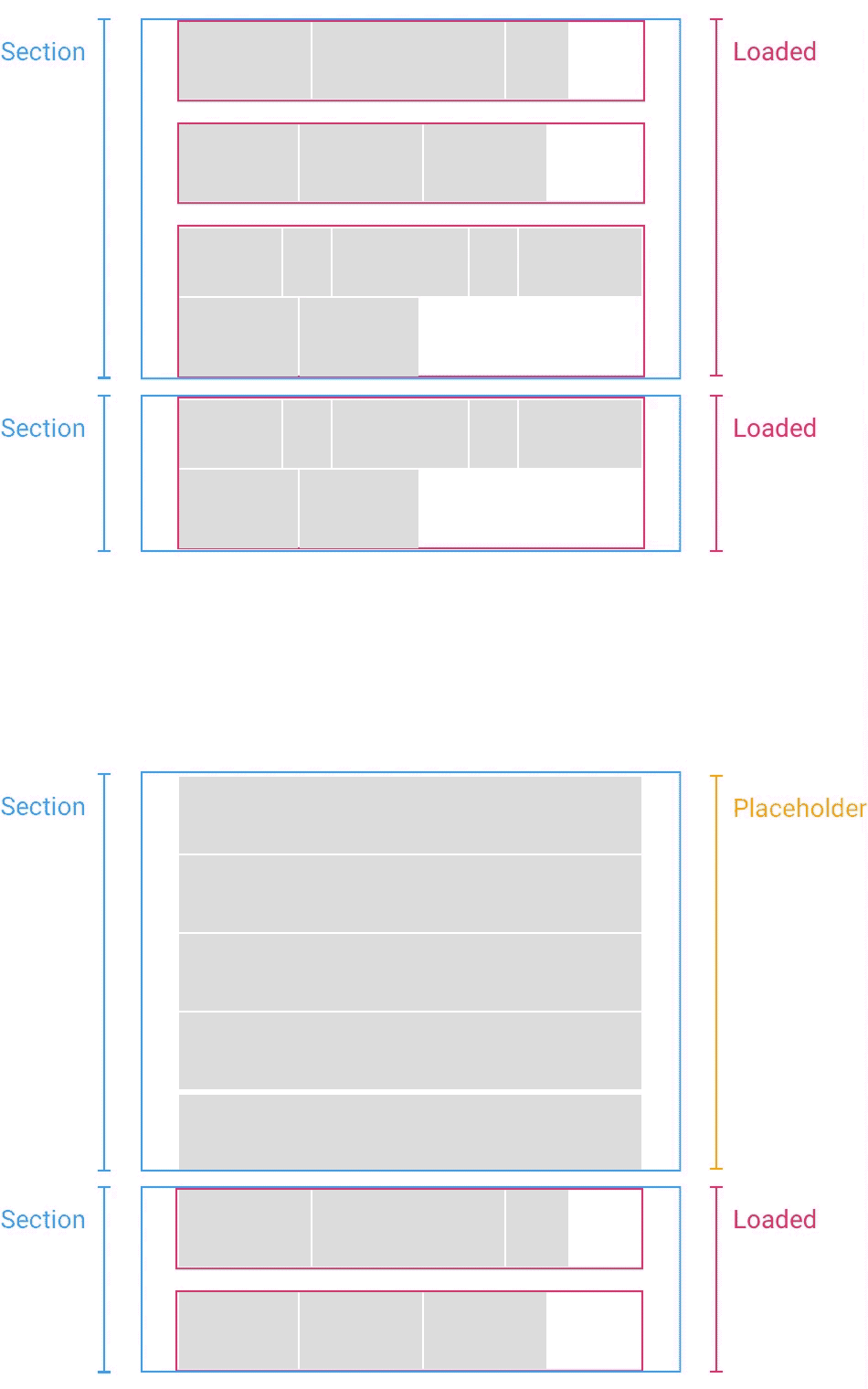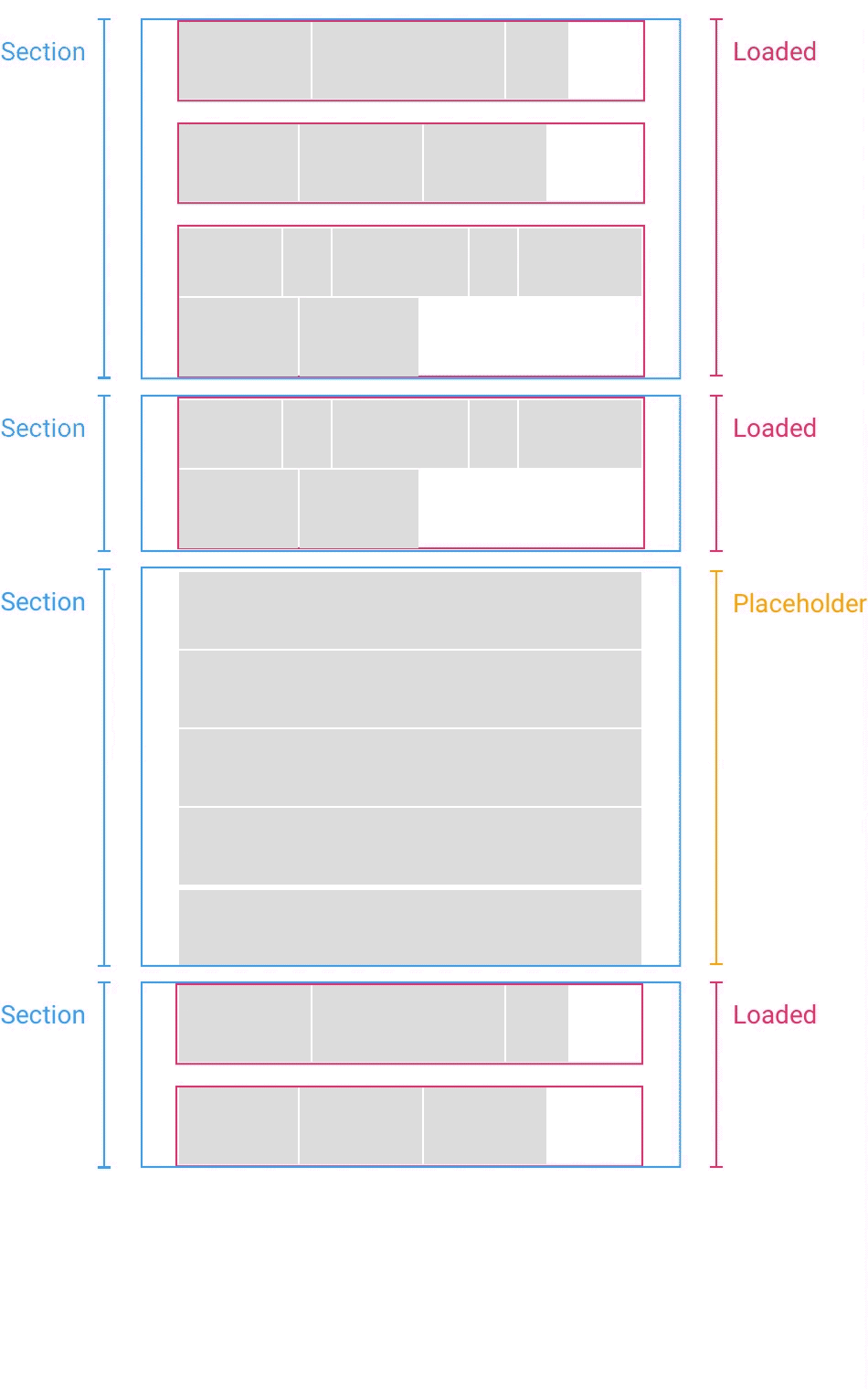
(когда временная заглушка (Placeholder) заменяется загруженным разделом (Loaded), координаты нижележащих разделов пересчитываются — прим. перев.)
Нехитрый трюк состоит в том, что когда вы наконец загружаете раздел, вы высчитываете разницу между оценкой высоты и фактической высотой. Если разница есть, вы просто сдвигаете все разделы ниже на эту величину. Если вы загружаете разделы, которые находятся выше позиции скроллинга, бывает нужно обновить и ее саму. Но всё это можно сделать за считанные доли секунды, за один кадр анимации, так что пользователь никакой разницы не заметит.
2. Раскладка на всю ширину
Все известные мне картиночные раскладки на всю ширину используют один остроумный, хоть и довольно простой, подход: они считают нормальным, если ряды картинок будут разной высоты. Все фото в одном ряду масштабируются до одной высоты, все ряды имеют одну ширину, но любые два ряда различаются по высоте, и разница обычно не очень заметна.
Отказавшись от единой для всех высоты, можно сохранять пропорции всех картинок, сохраняя при этом равномерно распределенную сетку фиксированной ширины. Алгоритм для этого вовсе не сложен, выбираете максимальную высоту ряда и затем масштабируете фото одно за другим к этой высоте, прибавляете их ширину к общей сумме, и каждый раз, когда эта сумма превышает ширину окна, уменьшаете все фото в ряду, пока он не впишется в ширину (при меньшей высоте).
Например, раскладываем 14 снимков:

Это довольно «лобовое» решение, но оно хорошо работает: его использовал Google+, его вариант использует поиск Google, а Flickr любезно открыл исходники своей реализации его же в 2016-м (у них она чуть умнее и проверяет, не лучше ли будет взять на один снимок меньше и увеличить размер, либо взять на один снимок больше и уменьшить). Код может быть буквально таким простым:
let row = [];
let currentWidth = 0;
photos.forEach(photo => {
row.push(photo);
currentWidth += Math.round((maxHeight / photo.height) * photo.width);
if (currentWidth >= viewportWidth) {
rows.push(row);
row = [];
currentWidth = 0;
}
});
row.length && rows.push(row);
Однако, поскольку я сначала беспокоился (хоть и зря) о том, чтобы оценка лучше совпадала с окончательной раскладкой, я стал искать более сложное решение и по ходу дела придумал кое-что получше.
По моей теории, после того, как мы «прикинули» будущую раскладку, нам была нужна возможность уместить фотографии в эту область. По сути это задача о переносе строки, во многом похожая на раскладку текста (перенос слов в тексте для выравнивания абзаца). Алгоритм переноса строк Кнута—Пласса — хорошо документированный подход из динамического программирования, который, как мне казалось, можно адаптировать для раскладки фотографий.
Он не разбирается по очереди с каждой строкой, а раскладывает весь раздел как единое целое, так что на каждую строку могут влиять и последующие.
Всё это в нем достигается комбинацией боксов, клея и штрафов. Боксы — это неделимые блоки, которые надо позиционировать (обычно слова, но иногда символы), клей — блоки, которые можно растягивать или сжимать (обычно пробелы в строке), а с помощью штрафов можно минимизировать что-либо нежелательное (часто это перенос слов или разрыв строк).
На следующей диаграмме видно, как клей между боксами оказывается разного размера по строкам.

Раскладка текста — боксы и клей
У раскладки фотографий есть некоторые отличия, но на деле они лишь упрощают ее. Для текста есть намного больше приемлемых вариантов — можно менять пробелы между словами, даже между буквами в слове, и можно переносить слова по частям. В случае фотографий разнобой отступов между ними будет сразу бросаться в глаза, а переносить фотографии по частям вообще бессмысленно.
Есть хорошие статьи о том, как алгоритм работает с текстом, но вот как мы адаптировали его для фото.
Снимки стали боксами, мы смогли полностью отказаться от понятия клея, и штрафы тоже удалось упростить. Хотя, если еще раз подумать, лучше подошла бы аналогия, что мы отказались от боксов, а фотографии были клеем (т.е. гибкая часть нашей раскладки — фотографии, а не пробелы). Может, это были просто клейкие боксы?
Мы не станем менять отступы между снимками, а возьмем на вооружение подход других галерей на всю ширину и будет подгонять высоту рядов. Чаще всего будет несколько мест, где можно начать новый ряд, если делать это раньше, ряды будут выше (с увеличением до заполнения ширины), если позже — ряды будут ниже (с уменьшением до заполнения). Рассмотрев все возможные перестройки рядов, мы можем найти ту, что окажется ближе всех к нужному нам размеру области.
Это значит, что нам нужно учесть три главных фактора: идеальную высоту ряда, максимальный коэффициент сжатия (насколько можно уменьшить высоту ряда по сравнению с идеальной) и максимальный коэффициент растяжения (насколько можно ее увеличить).
Алгоритм работает так: проверяет фото одно за другим, ища возможные разбивки по рядам — т.е. группы снимков, высота которых при масштабировании до заполнения ширины окажется в допустимом диапазоне (максСжатие ≤ высота ≤ максРастяжение). Каждый раз, когда он находит допустимый разрыв, он добавляет его в список возможностей, ищет все допустимые разрывы оттуда и так до тех пор, пока не просмотрит каждый снимок и все возможные разбивки по рядам. Например, для тех 14 снимков допустимый ряд может закончиться после 3 или 4 снимков, и при разрыве на 3-м появятся допустимые разрывы на 6-м или 7-м, а при разрыве на 4-м — допустимые разрывы на 7-м или 8-м. Все они представляют собой совершенно разные, хоть и отвечающие требованиям, раскладки для сетки.

Снимки, после которых возможен перенос (разрыв)
Заключительная часть — рассчитать показатель неудачности для каждого ряда. То есть насколько он неидеален. У ряда идеальной высоты показатель неудачности 0, а чем сильнее его пришлось сжимать или растягивать, тем показатель неудачности выше. Окончательная цена каждого ряда (сейчас станет понятно, что это) рассчитывается по штрафным баллам, в качестве которых часто используется куб или квадрат неудачности плюс еще какие-то штрафы (напр. за разрывы строк). Есть много статей о том, как лучше рассчитывать неудачность и штрафные баллы, в нашем случае мы используем степень отношения каждого ряда к максимальному сжатому/растянутому размеру (степенная функция сильнее штрафует ряды, очень далекие от идеала).
После прогона алгоритма у нас оказывается граф, в котором каждая вершина представляет собой возможный снимок для переноса, а каждое ребро представляет собой ряд (для любой вершины может быть несколько ребер, что означает, что при отсчете от любого снимка может быть несколько возможных мест разрыва). Каждому ребру можно назначить цену (значение штрафных баллов).
Например, для наших 14 фотографий, целевой высоты ряда (180px) и данной ширины окна (1120px) он нашел 19 возможных рядов для разбивки (ребер), приводящих к 12 уникальным перестроениям сетки (или маршрутам в графе). Ниже изображены все уникальные ряды и те ряды, с которыми они могут соединяться. Голубой маршрут — наименее плохой (могу ли я сказать лучший?) из них. Если проследить за линиями, видно, что каждая комбинация создает полную сетку, содержащую все фото — никакие два ряда не совпадают, и никакие две сетки не совпадают.
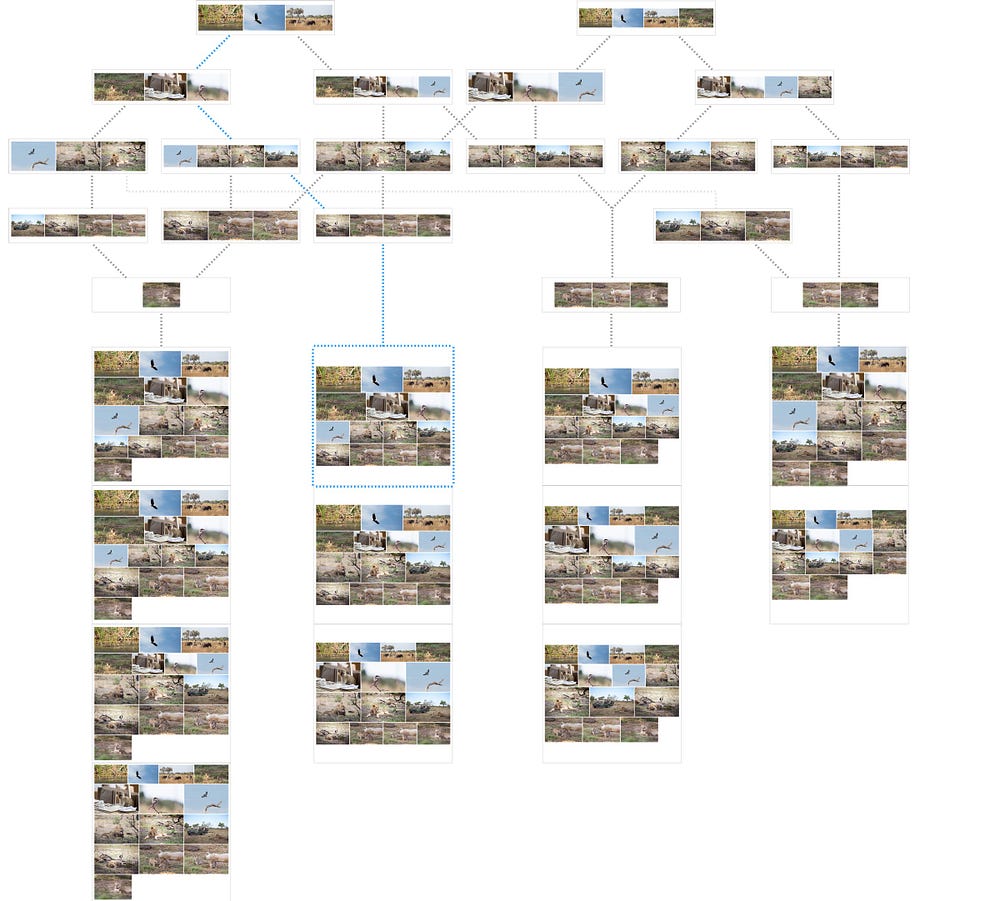
Уникальные комбинации рядов и сеток для 14 снимков
Найти оптимальную сетку для снимков (т.е. ту, где плохих рядов в сумме меньше всего) оказывается так же просто, как рассчитать кратчайший маршрут в графе.
На наше счастье, граф, который у нас получился — это так называемый направленный ациклический граф, в котором не бывает циклов и который можно обходить только в одном направлении (т.е. вершины/фотографии не повторяются). Это значит, что рассчитать кратчайший маршрут можно за линейное время (что в переводе с компьютерного значит быстро). Более того, на деле мы можем рассчитывать кратчайший маршрут еще во время построения графа.
При расчете длины маршрута мы просто суммируем цены, которые назначили каждому ряду, и каждый раз, найдя связанное с вершиной новое ребро, проверяем, не даст ли оно более короткого маршрута от этой вершины до начала. Если да, то запоминаем его.
Вот иллюстрация того, что компьютер «видит» по мере обхода этих 14 фото — верхняя строка показывает, какие фото он рассматривает в данный момент (начальный и конечный снимки ряда), граф под ним показывает, какие места разрыва он обнаружил, какие ребра соединяет, и в каждой точке он подсвечивает розовым текущий кратчайший маршрут для каждой вершины. По сути это просто еще одно представление графа с картинками, показанного выше — каждое ребро между квадратами соответствует одному из тех уникальных рядов.
Начав с первого снимка, он находит допустимое место разрыва по индексу 2, с ценой 114. Затем он находит еще одно допустимое место разрыва по индексу 3, с гораздо более высокой ценой 9483. Теперь ему надо проверить эти два новых индекса (2 и 3), где может быть перенос для них. Считая от 2, он находит 5 и 6, и к этому моменту кратчайшим маршрутом до 6 остается путь через 2 (114 + 1442 = 1556), так что он помечает его. Когда для снимка 3 снова находится маршрут к 6, мы снова проверяем цену, но поскольку исходный маршрут к 3 был таким дорогим, общая цена (9483 + 1007 = 10490) означает, что 6 по-прежнему хранит свой выбор в пользу 2. Ближе к концу анимации вы увидите, как первоначальный маршрут к 11 окажется неидеальным, и после учета вершины 8 алгоритм переключится на другой.

Поиск оптимальной комбинации рядов для 14 фото
Так мы поступаем со всем набором снимков, пока не дойдем до последнего (индекс 13). К этому моменту кратчайший путь (и лучшую раскладку) можно найти, следуя по кратчайшему маршруту, что мы пометили по ходу дела (и покрасили голубым в анимации).
Вот сравнение того, что построил «лобовой» алгоритм (слева) и того, чего добился алгоритм переноса строк (справа). Обоим была задана целевая высота в 180px. Можете отметить два занятных момента, один — что при раскладке «в лоб» ряды только уменьшаются, и второй — что раскладка переносами с той же легкостью может их увеличивать. Однако алгоритм переносов строк построил сетку, гораздо более близкую к целевой высоте.

Сравнение подходов к раскладке, при целевой высоте в 180px
В ходе тестирования мы заметили, что алгоритм переноса строк, который мы назвали его FlexLayout, т.е. гибкой раскладкой (не путать с флексбоксами в CSS — прим. перев.), строит и объективно, и субъективно более удачные сетки. Он стабильно порождает сетки более равномерной высоты (ряды меньше различаются между собой), и средняя высота ряда в них намного ближе к требуемой. И он гораздо лучше справляется с панорамами и другими особыми случаями, которые часто сбивают «лобовой» алгоритм с толку — потому что при «лобовом» подходе панорамное (сверхширокое) фото добавляется к первому рассматриваемому ряду, и поэтому часто слишком сильно уменьшается, потому что в этом ряду уже было немало снимков, тогда как с гибкой раскладкой рассматриваются все возможные разбивки по рядам,и те, в которых панорама слишком уменьшена, получат высокие значения неудачности, так что в итоге скорее будет выбрана раскладка, где панорама занимает отдельный ряд в одиночестве или с минимумом соседей.
Это может значить, что несколько рядов получатся чуть-чуть хуже (на несколько пикселей дальше от целевой высоты), чтобы один ряд не оказался намного хуже (чересчур низким или чересчур высоким). Это минимизирует неожиданности.
На количество возможных раскладок влияет много факторов. Один из важнейших — если снимков больше, но его может ограничивать и ширина окна, и фактические параметры сжимаемости и растягиваемости тоже весьма влияют.
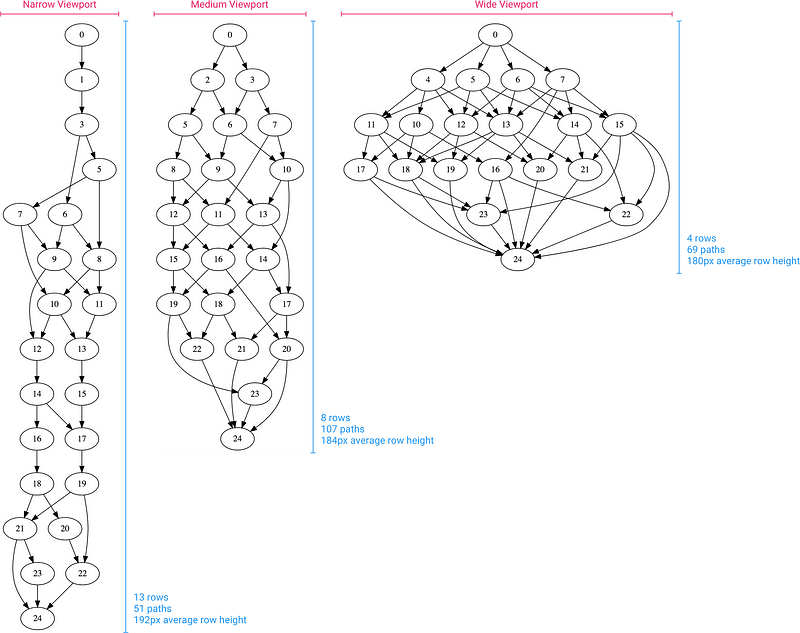
Уникальные раскладки для 25 снимков
Можете получить наглядное представление об этом, взглянув на графы для 25 снимков для узкого, среднего и широкого окна. В узком окне мало мест для разрыва, но нам понадобилось много рядов, в среднем окне мест для разрыва больше, а в широком окне, хотя мест для разрыва еще больше, нам не нужно так много рядов, так что вариантов разбивки там оказалось даже меньше.
Общее число уникальных раскладок растет с количеством снимков экспоненциально. Я посчитал реальные уникальные маршруты для средней ширины окна для набора снимков и получил:
5 фото = 2 маршрута 10 фото = 5 маршрутов 50 фото = 24136 маршрутов 75 фото = 433144 маршрута 100 фото = 553389172 маршрута
Для 1000 снимков их получилось слишком много, чтобы компьютер смог измерить, так что точно подсчитать уникальные маршруты он не смог (надо же как занятно, что алгоритм в этом случае может практически мгновенно понять, что нашел лучший маршрут, но удостовериться в этом за разумное время он не может).
Можно оценить число уникальных разбивок, взяв среднее количество возможных разрывов в ряду и возведя в степень вероятного числа рядов. Типичные размеры окна допускают 2–3 разрыва в ряду, и если в большинстве рядов около 5 или более снимков, можно прикинуть число раскладок как 2.5^(количество/5).
Для 1000 фото это будет число, оканчивающееся 79 нулями. Для 1260 снимков будет гугол возможных раскладок.
Если «лобовой» подход рассматривает и каждый раз использует единственную раскладку, алгоритм переноса строк рассматривает миллионы, миллиарды, триллионы и больше уникальных раскладок, выбирая наилучшую из них.
Если вам интересно, он еще и очень быстр. Раскладка 100 фотографий занимает 2 тысячных доли секунды (2 мс). На 1000 фото уходит 10 мс, на 10000 фото — 50 мс, и на 1 миллион фото нужно лишь целых 1,5 с (мы проверяли). Для сравнения, «лобовому» алгоритму для тех же чисел понадобилось 2мс, 3мс, 30мс и 400 мс — быстрее, но показатели вполне сравнимые.
Так что, хотя сначала мы всего лишь хотели выбрать из изрядного количества возможных раскладок ту, которая лучше всего вписывается в доступное место (т.е. подогнать раскладку к предварительной оценке), поскольку мы нашли способ плавно обойти нестыковку между оценкой и фактическим значением размера, он позволил нам всегда показывать пользователям наилучшую возможную раскладку.
Эта раскладка так хорошо работает, что с тех пор наша команда портировала ее на Android и iOS, и любые правки вносятся во все три реализации сразу.
И последний наш раскладочный трюк — мы прогоняем этот алгоритм дважды для каждого раздела. Первый раз мы прогоняем его, чтобы разместить все снимки в пределах сегмента, а второй раз — чтобы разместить сегменты в рамках раздела. Главная причина для этого в том, что иногда попадаются очень короткие сегменты, не заполняющие целого ряда, и алгоритм раскладки предлагает варианты, как их совместить — и как и со снимками, он рассматривает все возможные группировки, выбирая наилучшую.

Совмещенные сегменты
3. Скроллинг на 60fps
От листаемых фото и идеальных раскладок мало проку, если браузер не может с ними справиться. И сам по себе он и не справился бы — но, к счастью, мы можем помочь.
Один из важнейших факторов, почему сайты могут казаться медленными (помимо времени начальной загрузки) — то, насколько плавно они реагируют на действия пользователя, особенно скроллинг. Браузеры пытаются перерисовывать содержимое на экране 60 раз в секунду (60fps, от англ. frames-per-second — «кадров в секунду»), и если это получается, сайт выглядит и воспринимается очень плавным, а если нет — сайт кажется «дёрганым».
Чтобы поддерживать обновление с частотой 60fps, каждый кадр надо успеть отрисовать за 16 мс (1/60 с), и часть этого времени браузеру нужно выкроить «на себя» — ему надо обработать события, распарсить стили, рассчитать раскладки, превратить все элементы в пиксели, и наконец отрисовать их на экране — что оставляет приложению около 10 мс на все его действия. В эти 10 мс приложению нужна эффективность в решении его собственных задач и осторожность, чтобы не заставить браузер делать ненужную работу.
Поддержка постоянного размера DOM
Слишком много элементов — одно из худшего, что может случиться для быстродействия страницы. У этой проблемы два слоя: лишние элементы расходуют больше памяти браузера (напр., с 50-килобайтными миниатюрами 1000 фото — это 50 мегабайт, а 10000 фото, от которых Chrome раньше «падал» — было аж полгигабайта); кроме того, всё это добавочные детали, для каждой из которых браузеру нужно рассчитать стили и позицию, и свести слои во время раскладки.
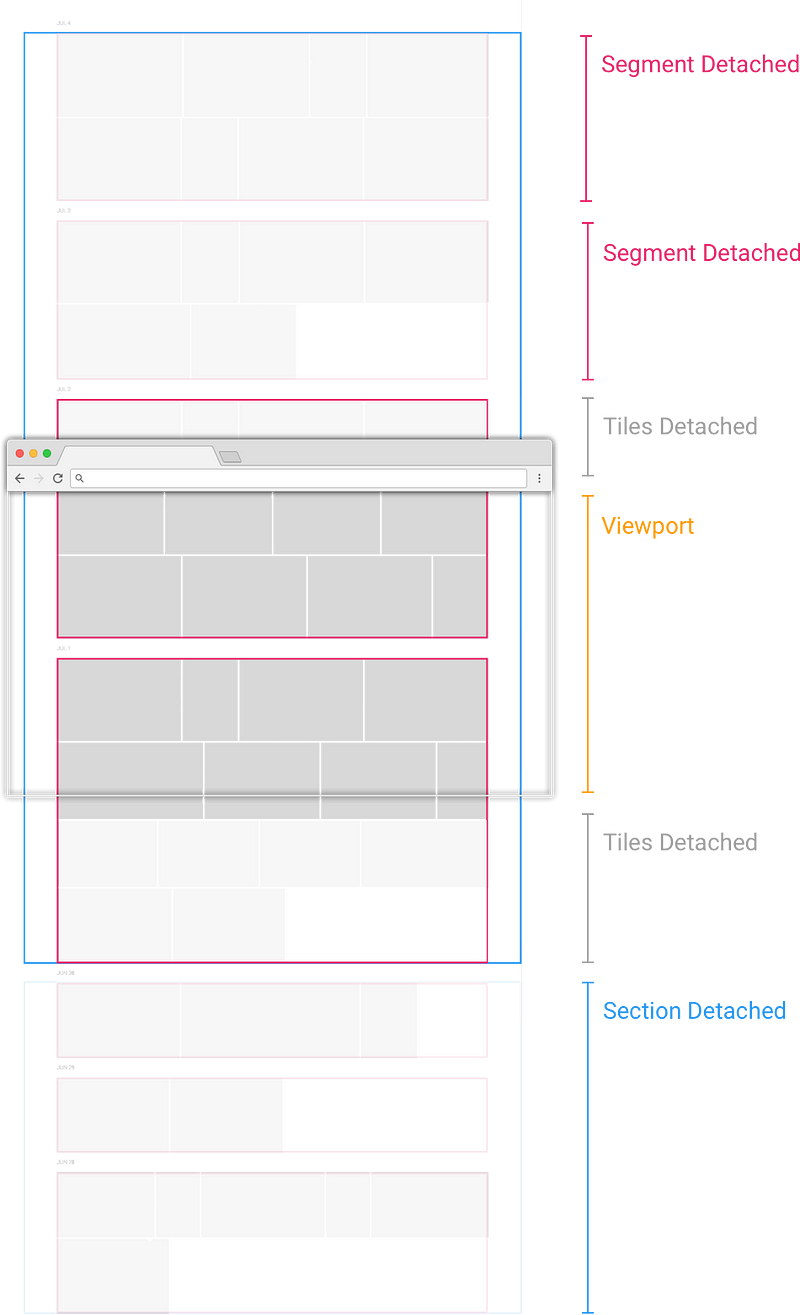
Убираем все необязательные элементы (элементы иерархии, которые удаляются из DOM при таком положении скроллинга, помечены словом «Detached» — прим. перев.)
Хотя у большинства пользователей в библиотеке будут тысячи фото, на экран обычно помещается лишь несколько десятков. Поэтому мы не помещаем каждое фото на страницу и оставляем его там, а каждый раз, когда пользователь скроллит, определяем, какие фото должны быть видимы, и обеспечиваем, чтобы они были в документе.
Каждое фото, которое было в документе, но перестало быть видимым, мы убираем.
При скроллинге страницы видны, скорее всего, не более 50 снимков, даже если вы скроллите десятки тысяч. Поэтому страница остается быстрой и вкладка не «падает».
А поскольку мы группируем фото по сегментам и разделам, мы часто можем поступить еще проще и убирать целые группы, а не снимки по одному.
Минимизируем изменения
На сайте Google Developers есть ряд отличных статей про производительность рендеринга и то, как использовать мощные инструменты анализа, встроенные в Google Chrome — я здесь коснусь некоторых аспектов, которые относятся к фотографиям, но и те статьи тоже прочитать стоит. Первое, что нужно уяснить — это жизненный цикл рендеринга страницы:

Пиксельный конвейер у Chrome (отработка скрипта, расчет стилей, раскладка макета, отрисовка слоев и их композитинг — прим. перев.)
Каждый раз, как на странице что-то меняется (обычно из-за JavaScript, но иногда и из-за CSS-стилей или анимаций), браузер проверяет, какие стили применяются к затронутым элементам, пересчитывает их раскладку (размер и положение), и затем отрисовывает все элементы (т.е. превращает текст, картинки и т.д. в пиксели). Ради эффективности браузер обычно разбивает страницу на части (называемые слоями) и рисует их по отдельности, так что ему остается выполнить еще последний этап композитинга (сведения, объединения) этих слоев.
Большую часть времени вам не придется об этом задумываться, браузер достаточно умен, но если вы постоянно меняете страницу в нем (например, то и дело добавляете и удаляете фотографии), то вам надо делать всё эффективно.
Разделы, сегменты и плитки позиционируются абсолютно
Первое, чем мы минимизируем обновления — мы позиционируем всё по отношению к родительскому элементу. Разделы абсолютно позиционируются по отношению к сетке, сегменты абсолютно позиционируются по отношению к своему разделу, и плитки (фотографии) абсолютно позиционируются по отношению к сегменту.
Смысл этого в том, что когда оценка высоты и ее реальное значение расходятся, нам не нужны сотни (а то и тысячи) изменений для всех нижележащих фотографий, вместо этого нам достаточно обновить положение верхнего края следующих разделов. Такая структура помогает изолировать каждую часть сетки от ненужных обновлений.
В современном CSS даже есть способ дать браузеру подсказку — ключевое слово contain (см. тж. статью о нем — прим. перев.) позволяет указать, до какой степени элемент можно считать независимым от DOM. Мы соответствующим образом помечаем разделы и сегменты.
/* Показывает, что ничто снаружи элемента не повлияет на раскладку внутри него, и наоборот. */ contain: layout;
Есть и другие опасные места для производительности, например, событие скроллинга может вызываться несколько раз за один кадр, как и событие ресайза (изменения размеров окна). Незачем заставлять браузер пересчитывать стили и раскладку для первых событий, если они всё равно потом изменятся.
К счастью, есть простой способ обойти это. Можно попросить браузер выполнить определенную функцию перед следующей отрисовкой с помощью window.requestAnimationFrame(callback). Это можно использовать в обработчиках скроллинга и ресайза, чтобы запланировать один обратный вызов вместо немедленного обновления (ресайз мы еще сильнее оптимизировали и откладываем обновление на полсекунды, когда пользователь уже определится с окончательным размером окна).
Еще одна частая ловушка — то, что называют постоянным перерасчетом макета. Как только браузер рассчитал раскладку макета, он кеширует ее, так что можно запросто очень быстро запросить ширину, высоту и позицию любого элемента. Но если вы что-либо меняете в свойствах, способных влиять на раскладку (напр. ширину, высоту, верхнюю или левую координату), вы тотчас же инвалидируете этот кеш, и если вы попытаетесь прочитать одно из тех свойств заново, браузер будет вынужден пересчитать раскладку заново (возможно, несколько раз за один и тот же кадр).
Это может по-настоящему вызвать проблемы в циклах, обновляющих много элементов (напр. сотни фотографий), если в каждом цикле вы читаете одно из раскладочных свойств, а затем меняете его (скажем, перемещаете снимки или разделы в нужные места), то вы на каждом шаге цикла вызываете новый перерасчет макета.
Простой способ избежать этого — сначала прочитать все нужные значения, а потом все значения записать (т.е. собрать операции чтения и записи в отдельные «пачки»). В нашем случае мы вообще обходимся без чтения значений, а вместо этого следим за размером и положением, которые должны быть у каждого фото, и позиционируем их все абсолютно. Во время скроллинга или ресайза мы можем прогнать все наши расчеты заново, исходя из наших отслеживаемых положений, и спокойно обновить их, не боясь постоянного перерасчета. Вот как примерно выглядит типичный кадр при скроллинге (всё вызывается только один раз):
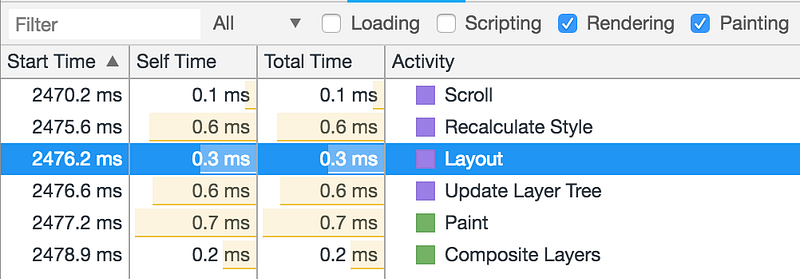
Порядок событий рендеринга и отрисовки для типичного обновления при скроллинге
Избегаем долго выполняющегося кода
За исключением веб-воркеров и некоторых нативных асинхронных обработчиков типа Fetch API, всё в пределах одной вкладки в основном выполняется в одном потоке — и рендеринг, и JavaScript. Это значит, что любой запущенный разработчиком код не даст перерисовать страницу до тех пор, пока не выполнится — например, долгий обработчик события скроллинга.
У нашей сетки больше всего времени занимают два действия — раскладка и создание элементов. Мы стараемся ограничить их оба лишь самыми необходимыми операциями.
Например, алгоритм раскладки занимает 10 мс для 1000 снимков и 50 мс для 10000 — больше, чем мы можем выделить в рамках одного кадра. Но если поделить нашу сетку на разделы и сегменты, то обычно нам в один момент времени нужно строить раскладку лишь для считанных сотен фото (что занимает 2–3 мс).
Самым «затратным» событием раскладки должен быть ресайз окна браузера, потому что для этого придется пересчитать заново размеры каждого раздела. Вместо этого мы опять прибегаем к простому оценочному расчету, даже для уже загруженных разделов, и прогоняем полный алгоритм FlexLayout только для видимого в данный момент раздела. А полный расчет раскладки для других разделов можно отложить до того момента, как мы до них доскроллим.
То же самое происходит с созданием элементов — мы создаем плитки с фотографиями непосредственно перед тем, как они нам понадобятся.
Результат
Конечный результат всех этих усилий — сетка, которая большую часть времени поддерживает 60fps, даже если изредка пропускает несколько кадров.
Такой пропуск кадров обычно случается при крупном событии раскладки (наподобие вставке целого нового раздела), или когда браузер время от времени проводит сборку мусора на очень старых элементах.

Частота кадров во время скроллинга
4. Ощущение мгновенности
Подозреваю, большинство фронтендеров согласятся, что во многих хороших интерфейсах некоторую роль играет ловкость рук. Фокус в том, какие дымовые эффекты использовать для отвлечения и под каким углом установить зеркала.
Мой любимый пример такого — секрет, которым со мной поделились коллеги из YouTube. Когда они впервые реализовали прогрессбар навигации (красную полоску, которая появляется на самом верху, когда вы переходите на другую страницу), у них не было способа измерить прогресс загрузки, так что они просто анимировали его с типичной для большинства страниц скоростью, а затем он как бы «подвисал» возле конца шкалы вплоть до самой фактической загрузки страницы. Не знаю, нынешняя версия по-прежнему так притворяется или уже реально работает, но в том-то и дело, что это неважно.

Прогрессбар YouTube
Точность оказалась не так уж нужна, главное, что благодаря этому страница стала выглядеть отзывчивее.
В этом разделе я поделюсь некоторыми трюками, с помощью которых мы заставляем Google Photos казаться чуточку быстрее, чем на самом деле — особенно как мы маскируем время загрузки картинок.
Первый, и, наверное, самый действенный из наших приемов — это заранее подгружать контент, на который, по нашим прогнозам, вы вот-вот посмотрите.

(ближе к видимой части окна («Viewport») подгружаются миниатюры полного разрешения («Preload»), дальше — миниатюры низкого разрешения («Low res») — прим. перев.)
После загрузки любой видимой плитки мы стараемся выдерживать запас в одну страницу перед ней, чтобы миниатюры успели загрузиться, пока вы скроллите.
Однако, особенно на экранах высокого разрешения (где нужны миниатюры побольше), если вы скроллите быстро, сеть может не успевать выполнить столько запросов.
Мы справились с этим, загружая предельно крошечные миниатюры на 4 или 5 экранов вперед и подменяя их по мере приближения к видимой части окна.
Это значит, что если вы скроллите относительно медленно (с той скоростью, с которой можно рассмотреть все фото), то вы не увидите ничего подгружающегося, а если быстро листаете (и эта скорость наводит на мысль, что вы ищете какой-то снимок), мы можем дать вам достаточный визуальный контекст, чтобы помочь сориентироваться в поиске.
Это сложный компромисс между добавочной работой по загрузке контента сверх необходимого и лучшим впечатлением от интерфейса.
Мы учли несколько факторов. Первое — следить за направлением скроллинга и подгружать контент только в том направлении, куда движется пользователь. Мы также измеряем скорость скроллинга и не подгружаем полноразмерные миниатюры, как только решим, что вы быстро листаете, а с еще более высокого порога, если вы вообще пролетаете мимо какого-то контента, перестаем грузить и картинки низкого разрешения.
В каждом случае (с миниатюрами нормального и низкого разрешения) мы масштабируем картинки. В нынешнюю эпоху сверхчетких мониторов стало общепринятым загружать картинку вдвое большего размера, чем ей отведено на странице, а затем ужимать ее (так что на ту же площадь приходится больше пикселей). Для миниатюр низкого разрешения мы запрашиваем очень маленькие картинки, к тому же очень сильно сжатые (напр. с качеством 25%), а затем увеличиваем их.
Вот пример со спящим леопардом — картинка слева используется в полностью загруженной сетке (уменьшенная вполовину), а картинка справа — миниатюра низкого разрешения, которую вы увидите лишь при быстром скроллинге (ее мы увеличиваем).

Плитки обычной миниатюры и заглушки низкого разрешения
Обратите внимание также на размер в байтах. В миниатюре высокого разрешения было 71.2 Кб (после gzip-сжатия), а в заглушке низкого разрешения — только 889 байт (тоже с gzip). Миниатюра была в 80 раз тяжелее! Другими словами, одна плитка в сетке равнозначна 4 и более страницам временных заглушек.
Ценой совсем небольшой добавки к сетевому трафику мы можем дать пользователю гораздо более приятный интерфейс, сетку, которая всегда выглядит полной, и всегда дает визуальный контекст.
Последним штрихом с плитками низкого разрешения было то, как браузер должен их рендерить. По умолчанию, когда вы увеличиваете картинку, браузер ее немного сглаживает (центральная картинка ниже), но это выглядит так себе. Можно применить фильтр размытия (крайняя картинка справа), с ним виднее, что этого эффекта и добивались, но есть недостаток — фильтр дорого обходится в плане вычислений, и если применять его к сотням элементов, это отрицательно скажется на производительности рендеринга и скроллинга. Так что мы решили пойти в другую сторону и подправить вид при низком разрешении, потребовав от браузера оставить картинку пикселизованной (крайняя картинка слева). Сказать честно, не знаю, осталось ли это в в продукте по сей день, код несколько раз рефакторили.

Варианты рендеринга миниатюр низкого разрешения
Хотя в идеале пользователь вообще не должен видеть картинок низкого разрешения (разве что при быстром скроллинге), при замене их, когда они попадают в область просмотра, мы раньше использовали краткую анимацию, чтобы казалось, что они подгружаются (а не появляются внезапно). Это легко достигается накладыванием одной картинки на другую и анимацией прозрачности (от полной прозрачности до полной непрозрачности) — прием такого плавного перехода («кроссфейд», от англ. cross-fade) очень популярен в вебе, например, скорее всего, так делают все картинки из оригинала статьи на Medium. По-моему, кроссфейд при смене картинки низкого разрешения на нормальную с тех пор выключили, но при смене пустой (серой) плитки на картинку он всё ещё происходит.
Это дает вид, будто картинка подгружается. Мы сделали его быстрым (за 100 мс), чего как раз хватает, чтобы картинка появлялась не слишком резко, но и не казалось, будто пользователю делают какое-то одолжение. Ниже я замедлил анимацию, чтобы она стала нагляднее.

Переход при загрузке, замедленно
Мы используем этот прием еще раз при переходе от миниатюры к полноразмерному снимку. Когда пользователь кликает по плитке, мы немедленно начинаем загружать полноразмерную картинку и одновременно с этим начинаем плавно увеличивать миниатюру до размеров большой картинки. Когда большая картинка загрузится, мы накладываем ее поверх и анимируем прозрачность. Единственное отличие в этом случае, поскольку мы работаем с единственным элементом, мы можем позволить себе размытие более дорогим фильтром blur (что очень кстати, потому что пикселизация на больших картинках смотрится не так мило).

Переход от сетки с фотографиями к полноразмерному снимку
Во всех случаях, при проматывании фотографий, или при переходе к полноразмерному фото, мы стараемся, чтобы для пользователей всё работало плавно и сразу реагировало на все их действия, даже если контент еще не готов. Сравните с тем, как бы выглядело, если бы при клике на плитку либо появлялся белый экран, либо вообще ничего не происходило до самой загрузки фотографии.
Мы даже применили этот принцип к пустым разделам. Если помните, наша листаемая сетка загружает разделы лишь тогда, когда надо (хотя, как и с плитками, она пытается заранее подгружать соседние). Это значит, особенно если схватить ползунок скроллбара и резко потянуть вниз, можно попасть к разделам, которые еще не загружены — в сетке под них выделено место, но еще неизвестно, какие снимки там будут и как их там разложить.
Чтобы скроллинг выглядел естественнее, мы наложили на незагруженные разделы текстуру высотой с идеальный ряд снимков, чтобы она имитировала пустые плитки. Сначала она выглядела просто как ряды (картинка слева), но позже команда поменяла эту текстуру на ряды и колонки (картинка справа), что больше похоже на фотографии. Средняя картинка — то, что получается, когда раздел уже загружен, но плитки в нем — еще нет.
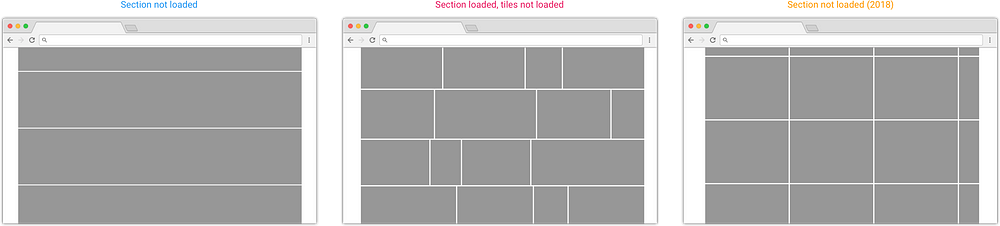
Паттерны сетки в разные моменты загрузки
Это как звериные следы для стадий загрузки фотографии — в следующий раз, когда будете быстро листать Google Photos, постарайтесь увидеть разницу.
Текстура была сделана не с помощью картинки, а силами CSS. Это дает еще один бонус, что ширину и высоту можно генерировать динамически, чтобы они соответствовали целевой высоте ряда для сетки.
/* Пока сетка не загрузилась, пусть она выглядит как ряды снимков 4:3. */
background-color: #eee;
background-image:
linear-gradient(90deg, #fff 0, transparent 0, transparent 294px, #fff 294px, #fff),
linear-gradient(0deg, #fff 0, transparent 0, transparent 220px, #fff 220px, #fff);
background-size: 298px 224px;
background-position: 0 0, 0 -4px;
У нас есть еще несколько трюков, но в основном они касаются очередности сетевых запросов. Например, мы не забиваем сеть запросом 100 миниатюр сразу, а группируем их по 10 или около того за раз, так что если пользователь внезапно начнет скроллить опять, то не окажется, что мы зря грузили 90 фотографий. Аналогично, мы всегда сначала грузим те миниатюры, которые попадают в видимую часть окна, и только потом остальные.
Мы даже проверяем, нельзя ли использовать вместо недостающей миниатюры уже имеющуюся, похожего размера — чаще всего это нужно после ресайза браузера, нередко у нас получается почти такая же сетка, как была, но ряды отличаются на считанные пиксели. Вместо того, чтобы загружать каждый снимок заново, мы слегка масштабируем те картинки, которые уже есть (и запрашиваем новые только в том случае, если разница слишком заметна).
Заключение
К каждой детали интерфейса Google Photos мы подошли с колоссальным старанием и вниманием, и сетка с фотографиями — лишь часть гораздо более значительного продукта.
Хотя на первый взгляд она может показаться простой, даже статичной, сетка почти постоянно думает — подгружает, кеширует, анимирует, создает, удаляет и отображает вам контент наилучшим образом, как только может.
Эффективность работы сетки (и ее постоянное улучшение) была и остается первоочередной задачей для команды разработчиков. У них есть подробный мониторинг для измерения частоты обновления кадров при скроллинге, времени загрузки разделов и картинок, и еще много других метрик. С каждым годом они всё улучшают быстродействие и удобство.
Вот небольшая запись с экрана, как выглядит скроллинг галереи. Если скроллить медленно, видны только картинки полного разрешения, при ускорении начинают появляться пикселизованные заглушки, которые превращаются в полноценные миниатюры, как только скорость опять уменьшается, а если резко дернуть ползунок, то на миг мелькают пустые серые плитки, пока сетка не подстроится.
Прокрутка и резкое пролистывание сетки с фотографиями
Большое спасибо моему бывшему менеджеру в Photos Винсенту Мо, кто, вдобавок к своей поддержке, снял все замечательные снимки из этой статьи (они же служили тестовым набором при разработке). А также Джереми Селиеру, руководителю веб-отдела Photos, и его команде, которая продолжает поддерживать и улучшать веб-интерфейс Photos по сей день.
Благодарности Лоре Гранка, Теону Харасимиву, Джереми Селиеру и Барбаре Элдридж.
P.S. Это тоже может быть интересно:
Хорошая статья, для общего развития. Интересно, как то, что МОЖНО сделать, так и то, насколько сложно, это сделать. Кроме всего прочего, нужно уметь пользоваться математикой. Поскольку знание математики у меня в зачаточной стадии, могу только в общем оценить — под капотом явно интересно!
С точки зрения самих гугл-фоток, был хороший повод его потестировать. В целом, мне понравилось. Вообще, я за то, чтоб было как можно больше пользовательских настроек и можно было делать сложные выборки, как в базе данных и добавлять произвольное количество метаинформации (в том числе сразу большому количеству фоток). А также настраивать, например, такие вещи, как идеальная высота ряда.
Также, возможно, исходя из идеальной высоты (а может и ширины, а лучше, даже, наверное, площади), делать, например, так: считается средний размер фотографии, а дальше миниатюры маленьких фотографий, незначительно уменьшаются, а больших — не значительно увеличиваются (можно выбрать как алгоритм, так и коэффициент), тем самым, видно, какие фотографии маленькие, какие большие. Можно, наверное, и ещё, что-нибудь интересное придумать :-)